Уже сегодня способность человека к созданию новой информации поражает воображение:
• в мире существует более 1 млрд веб-сайтов;
• ежедневно только в Instagram загружаются десятки миллионов фотографий;
• на то, чтобы посмотреть все видео, передаваемые в мире за 1 секунду, понадобятся годы.
При этом темпы роста объемов информации будут только увеличиваться: по прогнозу компании IDC1, к 2025 году совокупный объем информации, созданной человеком, вырастет в 10 раз и составит 160 зеттабайт2 (см. рис. 1). Взрывной рост возможен благодаря таким ключевым факторам, как: 1) доступность средств создания информации, прежде всего мобильных телефонов и планшетов, 2) увеличение скорости Интернета, в частности мобильного, 3) развитие облачных сервисов хранения информации.
Банки, безусловно, не стоят в стороне от этого процесса. Обычный розничный банк собирает широкий спектр информации о клиенте. Помимо анкетных данных он может хранить всю историю взаимоотношения клиента с банком, характер использования банковских продуктов, покупки по картам, поведение клиента на сайте банка, геолокацию из мобильных приложений и многое другое. И это не считая тех данных, которые могут предоставлять «официальные» источники: Росреестр, ФНС, БКИ и другие. Некоторые банки собирают более 10 тыс. переменных на одного клиента.
А кроме этого, все мы оставляем в открытом доступе информацию, большая часть которой является персональной: данные о нашем передвижении, любимых ресторанах, семье, образовании, профессиональных успехах, круге друзей, а также массу косвенных сведений о финансовом состоянии и даже психологическом профиле.
Все эти данные могут иметь отношение к процессу выбора банка, определению ключевых для клиента параметров продукта, способа коммуникации, которым лучше донести информацию, и многое другое. Перечень сложных процессов и неочевидных зависимостей не ограничивается только взаимоотношением клиента и банка. Как влияет прогноз погоды на загрузку банкоматов? Как влияет психотип клиента на вероятность просрочки? Как выделить мошенническую транзакцию из миллионов одинаковых операций по карте? Степень успешности ответов на эти вопросы определяется оптимально подобранным составом данных, среди которых ищется ответ.
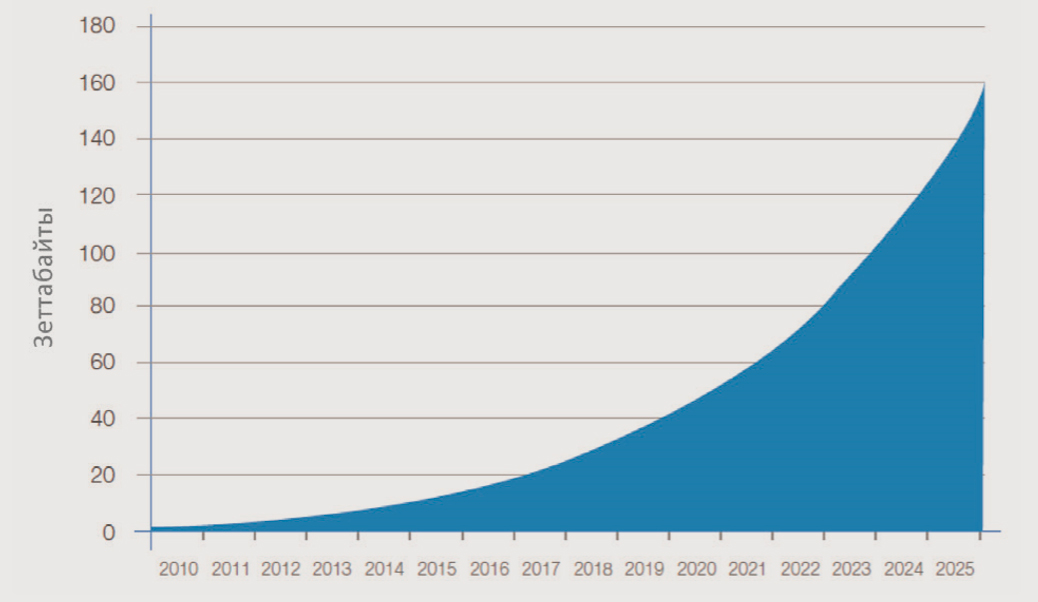
Рис. 1. Прогноз объема хранимой информации в мире
Очевидно, что человек уже не в состоянии в одиночку искать ответы на эти вопросы и, более того, не способен находить новые, постоянно изменяющиеся взаимосвязи. Современные процессы стали настолько сложными, что для эффективного управления необходимо держать в уме десятки и даже сотни параметров, находить между ними взаимосвязи и прогнозировать степень их влияния друг на друга и на ключевые процессы банка.
Однако наряду с ростом объемов необходимой информации повышается и производительность компьютеров. Вычислительная мощность, которую 20 лет назад мог дать только вычислительный центр размером со спортивный зал, теперь доступна пользователям персональных компьютеров.
Поэтому задачи, решаемые компьютерами, становятся все более сложными. Сложность повышается настолько, что все чаще и чаще компьютер принимает более взвешенные и обоснованные решения, чем человек. Поэтому необходимость в автоматизации процесса выработки рекомендаций или даже принятия решений очевидна.
Обучение компьютера способности принятия решений является одной из задач разработки искусственного интеллекта (Artificial Intelligence), то есть создания интеллектуальных машин или программ, способных выполнять функции, свойственные человеку. Созданные к настоящему времени интеллектуальные системы способны выполнять довольно узкие задачи, однако в них зачастую они превосходят человека.
Одним из самых известных примеров искусственного интеллекта являются программы для игры в шахматы или го. Прошло более 40 лет с момента, когда Алан Тьюринг написал на бумаге первую программу для игры в шахматы, прежде чем компьютер впервые обыграл чемпиона мира по шахматам. В 2016 году была создана программа AlphaGo, обыгравшая чемпиона мира по го. Подобные программы, помимо изучения всех партий, сыгранных человеком, сыграли огромное количество игр сами с собой и учились на основании этих виртуальных поединков. Однако эти программы не способны решать любые другие задачи, кроме тех, для которых они были созданы: они не могут отвечать на вопросы, не могут распознавать голос или изображения и т.д.
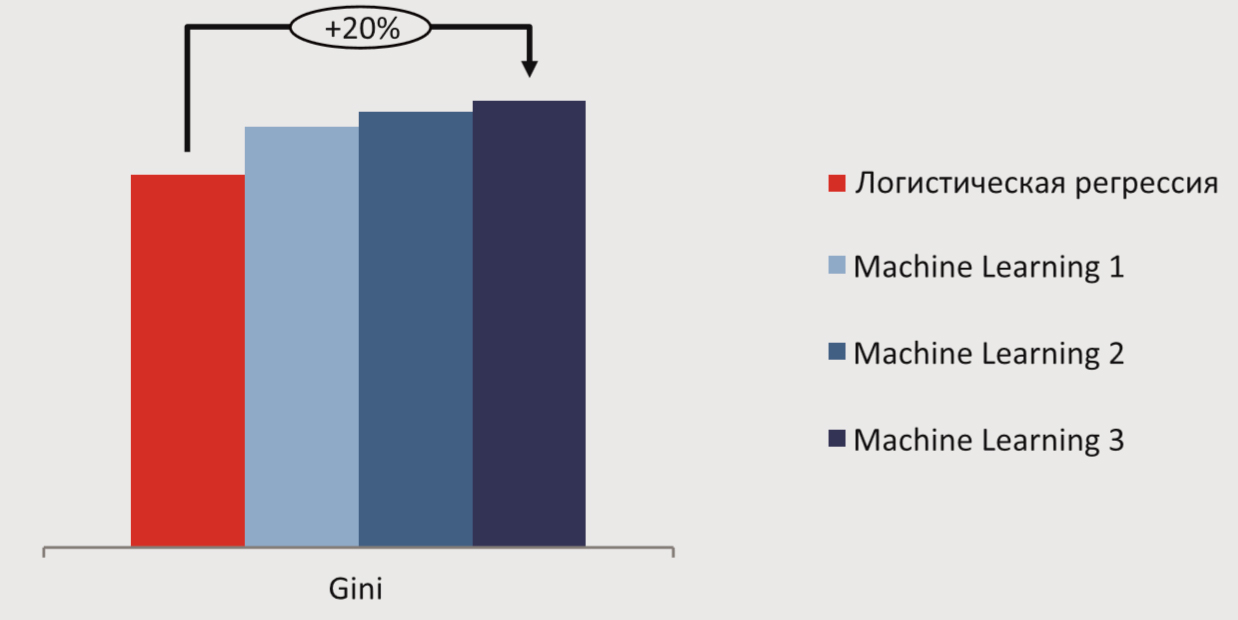
Рисунок 2. Методы машинного обучения значительно повышают качество моделей
Машинное обучение (Machine Learning) является направлением искусственного интеллекта, основным принципом которого является не прямое решение задачи, а получение машиной большого массива данных, на которых они «обучаются» решать большое количество сходных задач. Широкое распространение методов машинного обучения получили задачи прогнозирования. На основании данных, имеющихся о клиенте, предсказывается его поведение, склонность к тем или иным действиям. Одной из самых сильных черт машинного обучения является то, что в отличие от классических методов прогноз строится на основании нескольких десятков, а иногда и сотен переменных. Это позволяет достичь гораздо большей точности.
Одним из методов машинного обучения является глубокое обучение (Deep Learning). Оно используется для того, чтобы найти глубинные связи между переменными, чтобы улучшить качество решения задачи. Например, для задачи распознавания изображений необходимо найти такие алгоритмы, которые позволят эффективно отличать одного человека от другого с минимальной ошибкой. Классические методы машинного обучения могут не найти глубинную связь, а вместе с ней не найти и лежащую под этой связью зависимость. Однако следует отметить, что методы глубокого обучения крайне требовательны к вычислительной мощности, поскольку для решения задач используется многослойная структура нелинейных преобразований исходных данных.
Для начала использования технологий искусственного интеллекта не нужны большие инвестиции – многие задачи могут быть решены с помощью обычного персонального компьютера. Однако, с ростом объема анализируемых данных, требования к вычислительной мощности растут кратно.
Банк УРАЛСИБ видит огромный потенциал в применении методов машинного обучения и широко применяет их уже сейчас для оптимизации коммуникаций с клиентами, выявления и прогнозирования их потребностей (см. рис. 2). Для промышленного использования этих методов была построена инфраструктура:
1. Создана единая витрина данных для моделирования, которая насчитывает более 6 тыс. полей. Витрина наполняется автоматически и является единой базой для создания всех предиктивных моделей.
2. Мониторинг качества моделей автоматизирован и отслеживает все основные параметры. В случае необходимости модели автоматически калибруются.
3. Методы построения моделей унифицированы, что позволяет избежать «зоопарка».
Принятые меры позволили минимизировать количество ручных операций и сократить время создания модели с нескольких недель до 1–5 дней. Это дало возможность оперативно тестировать различные методы моделирования и подстраиваться под запросы бизнеса. В результате качество моделей, построенных на одной и той же витрине, выросло на 10–12 пунтов GINI по сравнению с классической логистической регрессией.
В настоящее время все «боевые» модели склонности строятся с помощью методов машинного обучения и используются во всех процессах взаимодействия с клиентом: для определения склонности к покупке, реакции на стимулирующие акции, вероятности оттока и т.д.
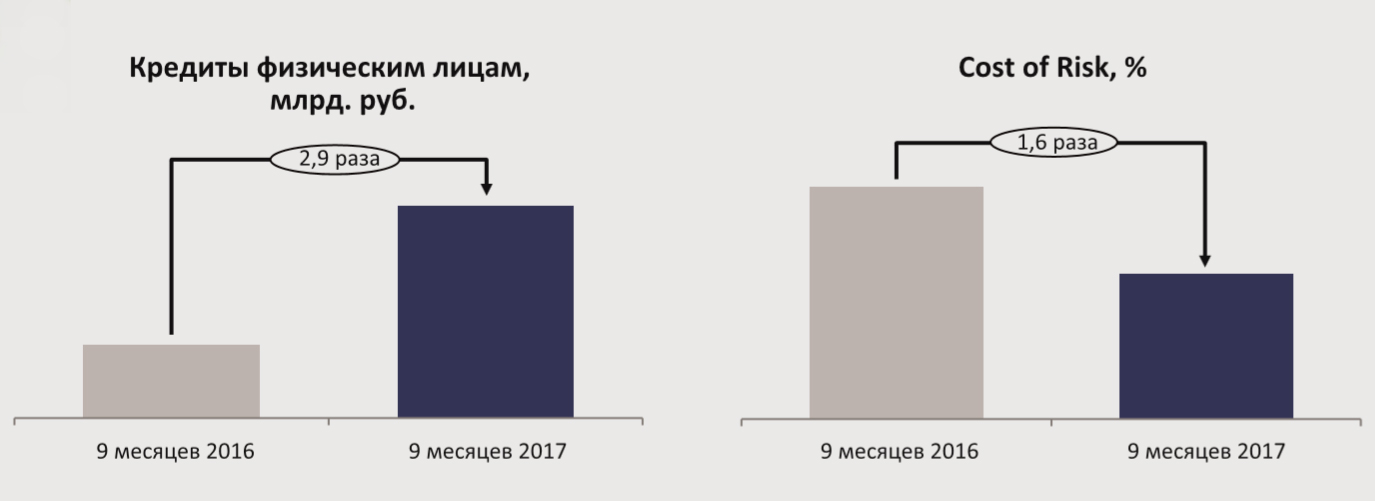
Увеличение качества прогнозирования сыграло значимую роль в росте результатов Банка УРАЛСИБ: за первые
9 месяцев 2017 года Банк выдал почти в 3 раза больше кредитов физическим лицам при значительном улучшении качества выдач по сравнению с аналогичным периодом 2016 года. За счет этого розничный банк в 2017 году вышел в прибыль.
В 2018 году Банк УРАЛСИБ сфокусируется на следующих направлениях:
1. Развитие методов глубокого обучения позволит найти скрытые закономерности между информацией о клиентах и их предпочтениями по выбору банка, продуктов, программы лояльности, а также по способу и времени коммуникации. Для этого перестраивается и обогащается витрина данных, а также прорабатываются возможности соразмерного наращивания вычислительных мощностей.
2. В части распознавания речи и изображений, автоматизации общения с клиентами в чатах и других областях, в которых появились явные лидеры рынка, дешевле брать на вооружение разработки сторонних компаний, чем пытаться создать свое решение с нуля. Для решения сложных задач необходимы не только вычислительные мощности, но и наличие специалистов по методам машинного обучения и их применению для решения сложных задач. Таким образом, в 2018 году Банк УРАЛСИБ сосредоточится на развитии машинного обучения в областях, где внутренняя экспертиза стратегически значима (например, риск-менеджмент) или где в настоящее время нет сильных продуктов сторонних компаний. Наработка опыта решения сложных задач даст возможность в будущем пользоваться технологиями создания искусственного интеллекта с учетом всех потребностей Банка УРАЛСИБ.
3. Создание инфраструктуры, позволяющей не только предугадывать потребности клиента, но и реагировать на них максимально удобным способом в режиме реального времени приводит к сокращению времени реакции банка на события в жизни клиента. Данный подход – единственно правильный для устойчивого роста, и его основой является нахождение сложных взаимосвязей между клиентскими данными, позволяющими лучше понять своего клиента.
4. Создание кросс-функциональных команд для точечного решения относительно небольших задач, в которых машинное обучение может принести пользу: оптимизация инкассации, открытие новых и релокация текущих отделений банка, анализ разговоров контакт-центра и выработка рекомендаций, создание финансового советника для клиентов и т.п.
Банк УРАЛСИБ активно внедряет технологии искусственного интеллекта для увеличения ценности коммуникаций с клиентами и улучшения клиентского сервиса. При этом регулярно тестируется применение новых методик анализа данных в областях, где раньше решения принимали люди.
Резкое расширение сфер применения машинного обучения и глубокого обучения является свидетельством смены базовых методов работы с клиентской базой (будь то физические или юридические лица) и управления процессами внутри организации. Необходимо регулярно выявлять области бизнеса с потенциалом для улучшения, проверять новые гипотезы и тиражировать те из них, которые принесли максимальный результат. И чем быстрее будут проверяться новые идеи, тем быстрее будут найдены и внедрены наиболее эффективные из них. Качество создаваемых идей и скорость их проверки являются одним из самых важных конкурентных преимуществ в современном мире.
Рост объема информации и появление все новых источников данных дает большой потенциал для использования технологий искусственного интеллекта и не оставляет шансов остаться в стороне от их применения в повседневных процессах любой организации. Компании, которые вовремя не распознают новые тенденции развития рынка, рискуют повторить путь корпорации, которая совсем недавно являлась лидером на рынке фотоиндустрии: успешная бизнес-модель перестала работать, конкуренты убежали вперед, а времени перестроиться уже не осталось – за полтора десятилетия лидер огромного рынка стал банкротом.
______________
1 IDC’s Data Age 2025 study, sponsored by Seagate, April 2017
2 1 зеттабайт равен 1021 байт